Can Speaker Recognition Systems Beat Humans?

July 30, 2019
By Pavel Jiřík in Blog
With all the evolution in deep neural networks and artificial intelligence, voice recognition systems are awe-inspiring these days. But how great is their ability to identify an actual person? Are they better than humans or easy to fool? We decided to find out.
What’s the Deal?
Speaker recognition (verification) systems identify people based on their voice characteristics. If you compare the voices of any two individuals side by side, they will never sound identical as every person has different vocal tract shapes, larynx sizes, and differences in other parts of their voice-producing organs. In addition to these physical differences, each speaker has their own way of speaking, distinct accent, rhythm, intonation style, pronunciation pattern, and choice of vocabulary.
As you can imagine, the recognition systems need to deal with a very complex set of voice characteristics to be successful!
At Phonexia, we use our own Speaker Identification System (SID) to check the speaker’s identity automatically. In its latest generation (SID L4), we use deep neural networks to capture long-term speaker characteristics in a fixed-length vector called a voiceprint. These voiceprints can afterward be compared using the log-likelihood ratio as an output.
Forensic experts leverage the power of SID directly in our Phonexia Voice Inspector (VIN) tool that helps them analyze large amounts of data at a speed that would be impossible to achieve manually so they can prepare all necessary reports for an investigation on time.
Typically, however, there are not that many forensic experts available, and many customers are forced to process vast amounts of data in some other way while staying within the limits of their financial resources. In such cases, they have two options:
- Use personnel to listen to audio recordings
- Use automatic speaker recognition software
As the latest generation of SID technology (L4 model) can process clean speech 30x faster than real time per single CPU, a human listener is no match for the automatic recognition system.
But what about the accuracy? Can the automatic speaker recognition system compete with humans?
Let’s Compare!
With the great excitement that always hits us when testing the capabilities of the latest deep neural networks against humans, we came up with the following test:
We compared the accuracy of both a human and automatic language-independent speaker recognition system on spoken English recordings from LibriSpeech corpus.
We sampled 314 target trials and 306 non-target trials from the subset of this dataset with recordings varying in length from 10 to 16 seconds.
In total, our evaluation set had 21 female and 21 male speakers. We did not use any cross-gender trials.
We tried to simulate the conditions in which automatic systems work as much as possible. So, we always evaluated the single trial—two recordings (one for the enrollment and the second one for the actual test) and let human listeners decide on a scale from -100 to 100, where -100 means “it is definitely a different speaker”, 0 means “I don’t know” and 100 means “it is definitely the same speaker”.
This way, we could measure the performance and compare it 1:1 to our fourth generation of the speaker identification system (SID L4) called Deep Embeddings™—the world’s first commercially available voice biometrics engine powered by deep neural networks.
Human listeners received a form with 20 trials and were able to finish it in approximately 15 minutes.
To better understand the challenge for both the automatic recognition system and humans, here is a list of some problematic trials. Can you guess whether the recordings belong to the same person or not?
Trial #1:
Trial #2:
Did you guess correctly that the first trial’s recordings belonged to two different people and the second trial’s recordings were from the same person? If yes, then congratulations!
Results
The Detection Error Tradeoff (DET) curve and a table with the Equal Error Rates (EER) are shown below. The performance of humans (Czech, not native English but with a proper understanding and communication skills in English) is much lower compared to the SID L4 model, yielding 8.87% EER compared to 3.06% EER achieved by the SID L4 system.
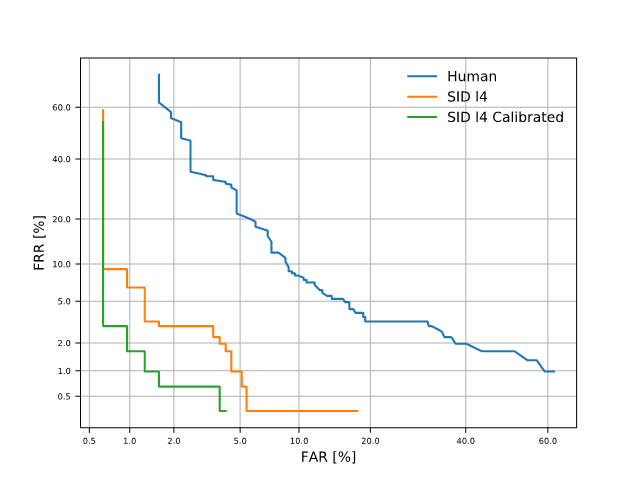

Also, as the SID L4 model supports calibration to in-domain data, we created an audio source profile (ASP) from more than 2,000 different speakers in LibriSpeech corpus to adapt it to in-domain conditions. Using this approach, we improved our results to 1.13 % EER, making only four false acceptances and three false rejections.
And the Conclusion Is…
Yes, automatic speaker recognition systems can beat humans 🙂


