Language Dependency in Voice Biometrics
January 29, 2019
By Lukas Bednarik in Blog
Can a Spanish spy speaking Hindi confuse an automatic speaker-recognition system? Which speaker characteristics are language dependent and which are language independent? A large part of the answer lies in the way these voice biometrics systems are created.
Voice Biometrics in Action
Voice biometrics is a technology used to identify a particular person based on the biological characteristics of their voice. Voice biometrics is used in a variety of situations: crime investigation, person identification to provide access to secured areas, airport identification or even caller verification in call centers.
In the last case, the same person can contact the same global company in different countries. The global market requires speech technology not to be limited to a particular language. These voice biometrics technologies must be robust enough that the company can verify a person's identity and provide the utmost security to that person's data.
Another use case is modern forensics. Voice data from a suspect's testimony can be in a different language than data from monitored phone calls. The prosecution of international criminals is an unusually severe act that requires technologies used for providing evidence to be extremely accurate and reliable.
It’s estimated that half of the world’s population speaks more than one language, which makes the need to create a language-independent voice biometrics system evident.
Problems of Language-independent Systems
Each second of speech is unique. This uniqueness is created by the speaker’s biological characteristics, emotions, spoken language and many other factors. The challenge of speaker-recognition systems is to identify only those characteristics, which are language and emotion independent, among other things. Speaker-recognition systems focus on the biological characteristics of speakers, which depend on the shape of their vocal tract, larynx size, and differences in other parts of their speech organs.
In order to be able to recognize speakers by their voice, the system's underlying neural network must be trained on appropriate data. This data must contain a suitable mix of multiple languages so the system can learn which speaker characteristics are language dependent and which are not.
In Phonexia, speaker-identification systems are trained on a mix of English, Vietnamese, Japanese, Uzbek and many other languages. This makes the Phonexia system language independent and robust.
Beyond Speaker Identification
There have been several attempts to train other language-independent systems. For example, Age Group Estimation can be used to estimate a speaker's age and can be employed, for example, in healthcare. People with a large difference between computed and chronological age are candidates for further examination because this difference could be caused by the symptoms of an emerging disease (for example, Parkinson’s disease).
Probably the most challenging area of language-independent systems is emotion detection. This technology has its stable place in call centers, where it creates an automatic statistic of happy/angry customers.
Small children, even before their language acquisition, prefer listening to happy speech. It is possible that “happy speech” is generalized across languages to some degree. There have been several studies that have pointed out that creating a language-independent system for emotion detection is feasible, but the accuracy of these systems in the real world is usually lower than the accuracy of language-specific systems. The creation of high-performing language-independent emotion detection remains a challenge for the future.
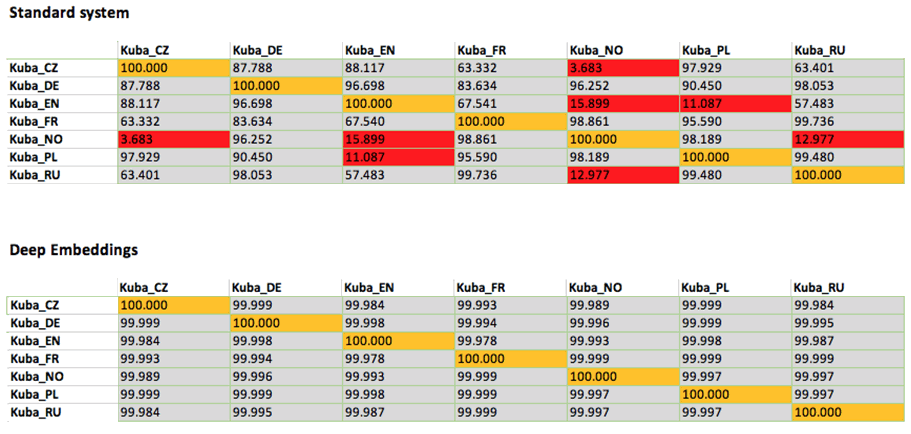
The Phonexia System
Only less than 1% of the world’s population are polyglots (people speaking five or more languages). Jakub Bortlík, a polyglot from Phonexia, tested Phonexia Speaker Identification on seven languages.

The latest Deep Embeddings voice biometrics technology for speaker identification correctly identified the speaker match/mismatch of each pair recording with 100% accuracy. Of course, aside from this demonstration, we can prove the performance of each technology on a large testing dataset.