New Phonexia Voice Biometrics More Than Doubles its Accuracy

March 27, 2019
By Miroslav Jirku in News
Phonexia releases the fourth generation of its voice biometrics technology called Phonexia Deep EmbeddingsTM. Deep EmbeddingsTM for Speaker Identification, now released in its production version, is the world’s first commercially available voice biometrics engine based exclusively on deep neural networks (DNN). The fourth generation uses deep neural networks together with more robust speaker models, leading to major improvements compared to the previous third generation.
Use of voice biometrics
Every performance improvement in voice biometrics makes the technology more usable in existing and new scenarios. Voice biometrics can be used in criminal investigations, financial services, virtual personal assistants, smart homes, IoT, automotive, industry 4.0, embedded devices (devices with no permanent connection to the Internet) and much more.
Over 99% accuracy on NIST SRE data set
The latest fourth generation of Phonexia voice biometrics technology has significantly improved its accuracy and has broken through the 99% accuracy barrier to a 0.96% Equal Error Rate, while the previous generation’s Equal Error Rate was 1.24% and was already considered as one of the most accurate on the market.
Phonexia Deep EmbeddingsTM achieved even more significant accuracy improvements when tested on multiple clients’ datasets. In almost all cases the accuracy was more than doubled compared to the previous iVector based generation. The chart below shows the accuracy improvements between Phonexia’s third and fourth generation Speaker Identification Equal Error Rate measurements.
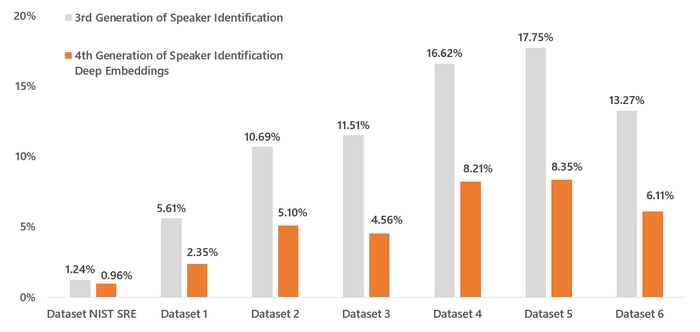
Equal Error Rate decrease between third and fourth generations of Speaker Identification
Required Identification Time cut by one third
In some use cases a short required identification time is extremely important. The latest Phonexia voice biometrics technology lowers the required identification time from 10 to 7 seconds, and the required enrolment time from 35 to 20 seconds. In specific use cases the time can be even shorter. Besides existing use cases in criminal investigations, this fact simplifies the use of voice biometrics in a host of other segments, amongst others, speaker authentication (speaker verification by voice) or fraud detection in voice-based client verification scenarios. The other use case worth mentioning is speaker identification in communication with voice bots or in industry 4.0.
More cross-language and cross-channel independence
Thanks to the use of deep neural networks together with more robust speaker models, the new voice biometrics technology performs much better for speaker identification even in conditions where the recordings for identification are captured from a different audio channel than that used for enrolment. The same positive results are also achieved in cross-language scenarios.
Four times higher processing speed and twenty-five times lower RAM consumption
Together with higher accuracy, less required time for identification and enrolment, and better cross-channel and cross-language dependency parameters, Phonexia Deep EmbeddingsTM also brings fundamentally faster processing speed and radically lower requirements on computer RAM. While the previous generation of speaker identification would process audio recordings five times faster than real time, the new generation processes audio recordings twenty times faster than real time which makes the new system four times faster. At the same time the new system consumes just 0.08GB of system RAM while the previous one, with lower accuracy, slower processing speed etc. consumed 2.07GB of system random-accessed memory.
All the above mentioned improvements are achieved concurrently. There is no trade-off between them.
| Technology Model | 3rd Generation of Speaker Identification | 4th Generation of Speaker Identification - Deep Embeddings |
|---|---|---|
| Equal Error Rate (EER) measured on NIST SRE data set | 1.24% | 0.96% |
| Equal Error Rate (EER) measured on client data set | 5.61% | 2.35% |
| Minimum speech signal for identification | 10 seconds | 7 seconds |
| Processing speed (ftRT = faster than real time) | 5 ftRT | 20 ftRT |
| RAM consumption | 2.07 GB | 0.08 GB |
Major improvements between third and fourth generations of Phonexia Speaker Identification
Deep EmbeddingsTM is currently offered in Phonexia Voice Biometrics, which is part of the Phonexia Speech Engine. For more information on this release please contact the Phonexia experts at [email protected]


