Forensic Voice Comparison—A Case for Speech Biometry
Introduction
From 2000 to 2018, I was the director of the largest European laboratory for Forensic Speech, Language, and Audio in the German Federal Criminal Police Office / Bundeskriminalamt (BKA).
The “hot topic” in my lab has always been forensic voice comparison (FVC), i.e., to compare one or several recordings of a so-called questioned or unknown speaker with one or several recordings of a suspect. Here is a brief overview of the approaches and methods that are currently used in FVC. Both have their pros and cons. One uses classical linguistic and phonetic methods, and the other uses modern speech biometry. For a comprehensive introduction and review see Jessen, Michael (2018): “Forensic Voice Comparison” in Visconti, Jacqueline (editor), Handbook of Communication in the Legal Sphere (pp. 201–218). Berlin, Boston: De Gruyter.
I think that in forensic casework, both approaches can complement each other in terms of their weaknesses and strengths.
Problems in the Forensic World
As you may have thought, FVC is no simple task. The reason is that speakers differ in many ways and that in contrast to the friction ridges of human fingers, there is no unique pattern that distinguishes one speaker from everyone else without any overlap. The difficulty of FVC is often increased due to numerous technical limitations such as short utterance durations, loud background noises, telephone-band frequency limitations, lossy compression, artifacts, etc., and due to disruptive behavioral influences like—to name some common ones—speech under the influence of stress or intoxication, voice disguise, different degrees of loudness or even different languages being used in the recordings to be compared.
As you can imagine, FVC gets even more difficult if a mismatch exists in these factors between the recordings under comparison.
The Auditory and Acoustic Framework
Until the introduction of modern speech biometry in the 2010s, there was broad consensus that forensic experts should use both auditory-based and acoustic-based linguistic and phonetic methods for the task. Let us call this the auditory and acoustic framework (AAF).
In this framework the forensic experts try to analyze a wide range of speaker characteristics, like voice quality, regional, social, or foreign-language accented dialect patterns, linguistic-phonetic and phonological details, speech tempo, speech rhythm and intonation, fundamental frequencies, vocal tract resonances, breathing and pausing behavior, disfluencies or other speech defects, etc.
Pros of the AAF
In the AAF, speakers are assessed and analyzed from as many linguistic and phonetic/acoustic perspectives as possible depending of course on the quality and quantity of the speech samples under investigation. The inclusion of multiple, maximally independent and uncorrelated voice, speech, and language features in the AAF adds to the robustness of conclusions. There is research concerning the discriminatory power of different speaker characteristics, i.e., concerning the intra- and inter-individual variation of speaker characteristics, and concerning the typicality or relative frequency of speaker-characteristic values. The results of this research can be used by the expert to interpret speaker similarities and differences appropriately. There are speaker characteristics that can be efficient killer criteria in FVC. For example, under certain conditions, speaker identity can be excluded categorically if there are genuine phonetic or linguistic incompatibilities between speakers, e.g., regarding different regional accents or other incompatible feature instantiations.
Cons of the AAF
Linguistic and phonetic analyses of similarities and differences between speakers are strongly dependent on subjective judgment and experience, i.e., on the individual expert skills, knowledge, and interpretation. Many of the linguistic and phonetic features analyzed in FVC are qualitative and not quantitative. In addition, acoustic measurements often cannot be interpreted unequivocally because population studies and valid background statistics are not available. Hence most labs cannot express FVC results numerically and instead use expression frameworks like identification/exclusion/inconclusive, or a-posteriori verbal probabilities, or verbal likelihood ratio scales. The method is largely language dependent. Thus, experts have to limit themselves to forensic phonetic and linguistic analyses in their native language and possibly one or two other languages, in which they have the skills. The method is labor intensive and time consuming with a tempo that needs to be measured in days or weeks rather than CPU minutes. Hence experts cannot regularly provide any results of testing which could demonstrate the degree of their validity and reliability in performing forensic voice comparisons.
Imagine, for example, a dataset of only 40 recordings with 20 speakers involved and in which there are two recordings per speaker. There are 780 comparisons to be made of which 20 are same-speaker comparisons, and 760 are different-speaker comparison. Automatic speaker identification (SID) can do that in minutes. Testing human experts with any statistically relevant dataset is unrealistic.
As a part of accreditation (ISO/IEC 17025:2017) and quality control, annual proficiency testing and collaborative exercises are being introduced in many European FVC laboratories. With sobering results, as had to be expected, specialists working within the AAF show considerable variation regarding discrimination and precision in voice comparisons.
Not only are voices occasionally misidentified or identities falsely rejected by the professionals tested. Even when they correctly agree as to the identity or non-identity of the questioned and the suspect voices, they more often than not differ considerably, e.g., in the degree of their probabilistic statements.
Automatic Speaker Identification (SID)
Forensic SID refers to a method of FVC that in its central processing stages operates automatically. The central processing stages consist of at least feature extraction, feature modeling, similarity scoring, and the computation of results.
In the early 2000s due to technological and conceptual improvements, SID started to get interesting for FVC for two reasons:
Firstly, because over the years automatic systems achieved better and better recognition rates when comparing forensically realistic speech materials like, e.g., foreign-language, text-independent, and telephone-transmitted samples.
Secondly, it turned out that the SID methodology organically fits with the contemporary Bayesian / likelihood-ratio approach to forensic inference, an effective and logically coherent way of interpreting and modeling forensic evidence in general. Compared with traditional human-based methods in FVC, the SID methodology provides a number of advantages
Pros of SID
Even though the selection and preparation of speech samples require judgments and activities to be performed by the expert, the level of human involvement /subjectivity in SID is greatly reduced in comparison to the AAF. Hence SID results are considerably less subjective and less reliant on skills, knowledge, and interpretation. SID can be regarded as a universal methodology. There are written down standards or guidelines controlling the technique, addressing important issues like measurements of system performance and method validation, forensic case assessment, evaluation and interpretation, reporting and quality assurance (i.e., Drygajlo, A., Jessen, M., Gfroerer, S., Wagner, I., Vermeulen, J. & Niemi, T. [2015]: Methodological Guidelines for Best Practice in Forensic Semiautomatic and Automatic Speaker Recognition). SID is basically repeatable. If different experts were to process the same speech samples with the same SID system and settings, the outcome would be identical. SID systems are straightforwardly testable owing to their high speed of processing. Hence one can easily determine how good they perform in different situations and understand what their limitations are. SID systems comply with judiciary standards like, e.g., US Federal Rule of Evidence 702, which includes requirements that testimonies are based on sufficient facts or data and that testimonies are the product of reliable principles and methods. SID meets these requirements since known and potential recognition or error rates can be established empirically and made fully explicit. SID systems present the results of comparisons as likelihood ratios (LRs). These are expressions of the ratio of how likely it is to have found the voice evidence if the samples were to have come from the same speaker against the likelihood of having found that evidence if they had come from different speakers. This approach of reporting the results is also used in DNA evidence and fits within the logically correct and appropriate Bayesian framework for expressing the strength of forensic evidence.
Cons of SID
In limiting themselves to acoustic features or vocal tract acoustics, current SID systems process only a fraction of speaker characteristics that can be used to discriminate between individuals. While achieving outstanding recognition rates even under forensic conditions, SID systems still commit errors in the form of false identifications or false rejections. Probably because of the anatomical differences between speakers being too small, vocal tracts not being rigid but moving in speech, and because in FVC they often have to deal with comparisons of random speech samples that are short, not fully representative, frequency limited, noisy, etc.
As experience shows, the optimum situation for the use of SID—that is not always met in FVC—is to compare recordings that share the same characteristics in terms of speech style, recording features, noise levels, and language.
Synthesis
In the view of the listed advantages and disadvantages of the AAF and SID frameworks, for now, a combination of both approaches, exploiting their respective strongholds and taking care of their deficits can be regarded as a reasonable approach to FVC.
In fact, the BKA has launched a combined AAF/SID approach in FVC to complement the advantages of both methods in order to increase the reliability and robustness of the final conclusion. There are similar approaches by speaker comparison laboratories in many other parts of the world.
Unfortunately, this combination is not easy. Phonetic and linguistic methods on the one hand, and biometrical methods on the other, not only differ regarding the respective prevalence of qualitative or quantitative assessments but also with regard to categorically different conclusion frameworks. There are feasible solutions, however.
Let me try to demonstrate with some examples of forensic casework and casework-related research, how SID can change a case, how speech biometry and forensic phonetics can be combined in casework, and that linguistic and phonetic information is valuable and can help to prevent SID errors.
Case 1
In a recent criminal case, a telephone recording of an unknown speaker had to be compared with a large number of suspect voices. The prosecution assigned the FVC task to an experienced private expert working within the AAF. After months of work, the expert found a match and declared “beyond a reasonable doubt” that there was identity between one of the suspect’s voices and the voice of the perpetrator.
This testimony, however, was not accepted in court because the judge had reservations regarding the expert’s qualification and regarding the subjective components involved in the method.
The prosecution then asked the BKA FVC laboratory to compare the two voices in question. Using a combination of the AAF and three SID systems, BKA experts found no support for the private expert’s view but consistent indications that the voices in question were different. As a result, the suspect was exonerated.
Case 2
In a recent criminal case, the BKA FVC laboratory was asked to compare approximately 50 questioned telephone calls with telephone recordings of two suspects A and B.
Based on their investigations, the police had already assigned one part of the questioned telephone calls to suspect A, and the other part to suspect B.
By using the AAF, the questioned telephone calls were separated and provisionally sorted into three different groups on the basis of their respective phonetic and linguistic characteristics: One group resembling speaker A, another group resembling speaker B, and one more group containing questioned telephone calls that experts found to be phonetically and linguistically different from both A and B or too short to be analyzed at all.
In the next step, the AAF and SID were used to compare every speech sample in group A with the telephone recordings of suspect A, and every speech sample in group B with the telephone recordings of suspect B. Both AAF-based and SID methods resulted in identifications in every case.
In court, the linguistic and phonetic results were reported verbally. The SID-results were reported as likelihood-ratios and explained to the court against the background of a case-specific validation study. This validation had been carried out to better interpret the measured log10LR of the questioned vs. suspect comparisons with regard to their magnitude and thus, with regard to their significance for the hypothesis of identity or non-identity.
For this, a collection of recordings that were compatible with the case recordings in terms of speech style, recording features, noise levels, language, and with clear speaker identities was used. Altogether, 23 same-speaker comparisons and 506 different-speaker comparisons with utterance duration of at least 20 seconds were evaluated.
In the final report, the validation results for the same-speaker comparisons and the different-speaker comparisons were represented as cumulative frequencies in a graph, which is referred to as a Tippett plot.
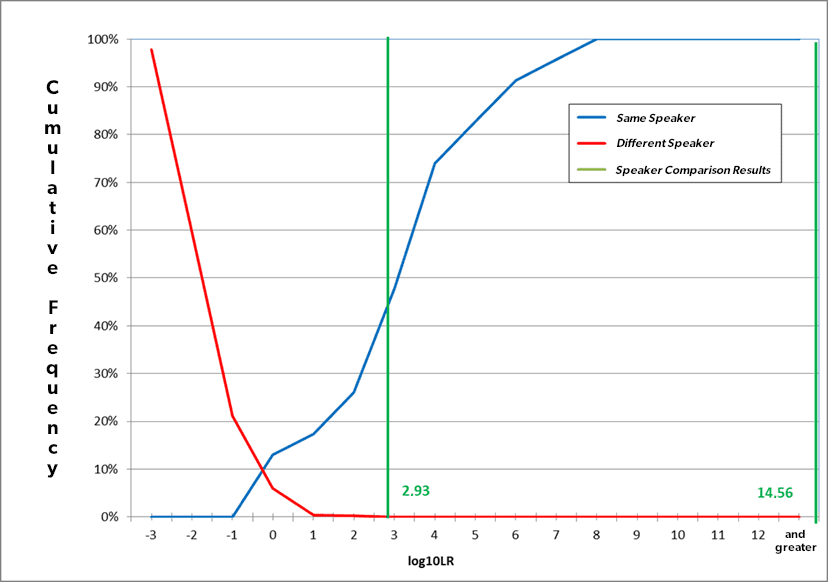
The curve falling from left to right (red in color) shows the percentage of different-speaker comparisons which exceed the log10LR value given on the x-axis. The curve rising from left to right (blue in color) shows the percentage of same-speaker comparisons which are below the log10LR value given on the x-axis. The vertical green lines show the minimum (2.93) and maximum (14.56) log10LR values observed with the comparison of all questioned and suspect speech samples in this case.
Since the analysis results of the SID method were numerical and the results reached within the AAF were not, both could not be combined into a final numerical conclusion. Instead, final conclusions were expressed verbally using verbal probabilities. Statements were decisively stronger though, as they would have been without SID.
Casework-Related Research
As a part of the method validations, SID (voice comparison software) was used to compare the voices of a large number of German Emergency-Center telephone operators who had been recorded all over the country to build a BKA database of different German regional accents.
For the test, a subset of this database was used that contained only one 1-minute recording per speaker. Since only different speakers were compared, no false rejections were to be expected. Based on 11,990 different speaker comparisons, SID (in 2017) delivered 121 false identifications (i.e., LLR > 1.2) corresponding with an EER of approximately 1%.
Interestingly, 72% of the false accepts were speaker pairs with dialectal differences that could unambiguously be classified as non-identical by regional accent analysis within the auditory and acoustic framework.


